OpenAI Audio Model Podcast AI Guide 2026: How BibiGPT Summarizes Any Audio in 30 Seconds
Deep dive into OpenAI's upcoming Audio Model and its revolutionary impact on podcast AI. Learn how BibiGPT leverages advanced audio understanding to summarize any podcast in 30 seconds with real-time transcription, podcast-to-article conversion, and AI-powered Q&A.
OpenAI Audio Model Podcast AI Guide 2026: How BibiGPT Summarizes Any Audio in 30 Seconds
Table of Contents
- The Audio Model Era: Why 2026 Is the Year of Podcast AI
- Three Core Capabilities of OpenAI's New Audio Model
- The Technical Revolution in Podcast AI Processing
- How BibiGPT Leverages Audio Models for Podcast Summarization
- Step-by-Step: Summarize Any Podcast in 30 Seconds
- What Audio Models Mean for Podcast Creators
- Podcast AI Tool Selection Guide
- FAQ
The Audio Model Era: Why 2026 Is the Year of Podcast AI
OpenAI is releasing its new Audio Model at the end of March 2026, marking a watershed moment in audio AI. With native support for real-time conversation, interruption handling, and an audio-first device roadmap, this model represents a fundamental shift from "transcribe first, understand later" to "directly comprehend audio." For the global podcast ecosystem producing hundreds of thousands of new episodes daily, this signals a transformative new era.
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
For years, the standard podcast AI pipeline has been "audio -> transcribed text -> text understanding." This approach has an inherent bottleneck: information loss during transcription. Tone, pauses, emphasis, emotional crosscurrents in multi-speaker conversations — nearly all of these are lost in plain text transcription.
The breakthrough of OpenAI's Audio Model is that it no longer needs to convert audio to text first. The model performs semantic understanding directly at the audio signal level, functioning like a human assistant who is genuinely "listening" to a podcast. For AI podcast summary tools, this represents a quantum leap forward.
According to industry data, the global podcast market surpassed $30 billion in 2026, with over 500 million weekly active listeners. Yet a core contradiction persists: podcast content consumption is extremely inefficient. A 60-minute deep-dive conversation might only contain 30% useful information density, but unlike articles, you cannot skim audio. This is precisely why tools like BibiGPT and other AI podcast summarizers exist — saving brainpower through computing power.
Three Core Capabilities of OpenAI's New Audio Model
OpenAI's Audio Model is not simply an upgrade to speech recognition — it achieves architectural breakthroughs across three dimensions. These capabilities will fundamentally reshape the technical foundation of podcast AI tools, enabling far more intelligent audio understanding than anything available today.
1. Real-Time Conversation with Interruption Handling
Traditional voice models use a turn-based interaction model: "you finish speaking, then I process." OpenAI's new model supports genuine real-time dialogue — it can understand semantics while you are still speaking and respond at appropriate moments. Crucially, it handles interruptions gracefully, which is essential for the multi-speaker crosstalk common in podcast conversations.
2. Audio-First Device Roadmap
The model establishes an explicit "audio-first" product direction, meaning more native audio devices (smart earbuds, in-car systems, smart speakers) will directly integrate AI audio understanding capabilities. Podcast listening scenarios will evolve from passive consumption to interactive comprehension.
3. End-to-End Audio Semantic Understanding
The most fundamental breakthrough is bypassing traditional ASR (Automatic Speech Recognition) entirely, extracting semantics directly from audio waveforms. This means the model can perceive a speaker's tonal shifts, emotional fluctuations, and prosodic features — all critical for understanding the true meaning of podcast conversations.
The Technical Revolution in Podcast AI Processing
The evolution of podcast AI tools can be divided into three distinct phases, each significantly improving users' ability to extract knowledge from audio content. Understanding this trajectory reveals the true value of the current audio model revolution.
Phase 1: Pure Transcription Era (2020-2023)
Early tools focused on speech-to-text conversion. After Whisper went open source, transcription costs dropped dramatically, but the output was still "a wall of text" requiring users to read and extract insights manually. BibiGPT supported podcast transcript generation during this phase, covering platforms like Apple Podcasts, Spotify, and Xiaoyuzhou.
Phase 2: Transcription + Summarization Era (2023-2025)
Large language models made "transcribe-then-summarize" possible. Tools would convert audio to text, then use AI to generate structured summaries. BibiGPT's smart deep summary became a standout feature of this era — automatically generating core insights, key timestamps, terminology explanations, and reflection questions.
Phase 3: Native Audio Understanding Era (2026-)
OpenAI's Audio Model inaugurates an entirely new paradigm: skip transcription, understand audio directly. This is not incremental improvement but a qualitative transformation — the model can detect sarcasm, understand subtext, and distinguish between host and guest perspectives.
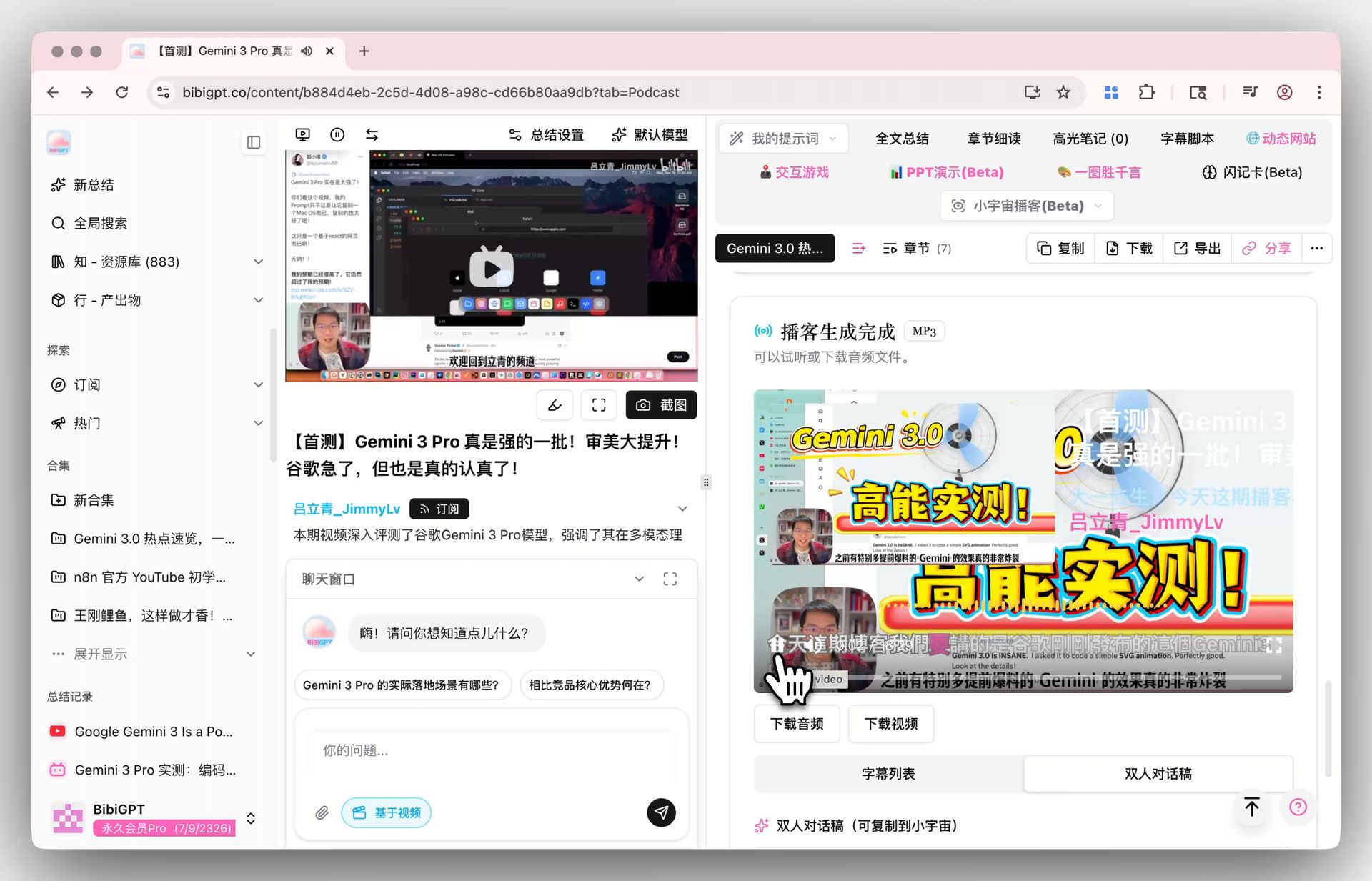 BibiGPT Podcast Summary Feature
BibiGPT Podcast Summary Feature
How BibiGPT Leverages Audio Models for Podcast Summarization
BibiGPT is the leading AI audio-video assistant, serving over 1 million users with more than 5 million AI summaries generated across 30+ platforms. As audio model technology evolves, BibiGPT's podcast processing capabilities are undergoing a significant upgrade cycle that will benefit every user.
See BibiGPT's AI Summary in Action
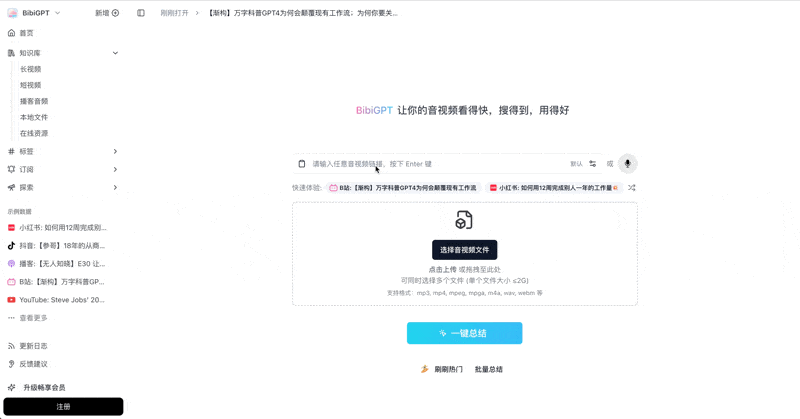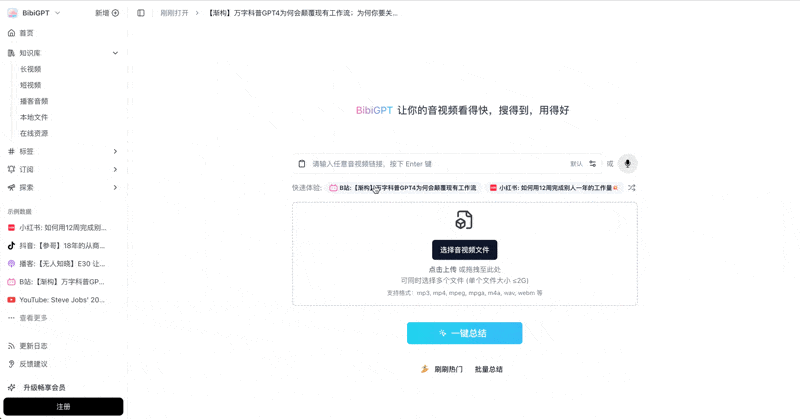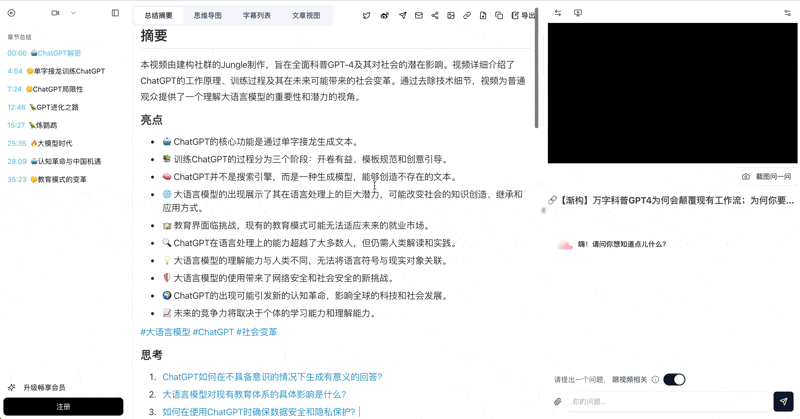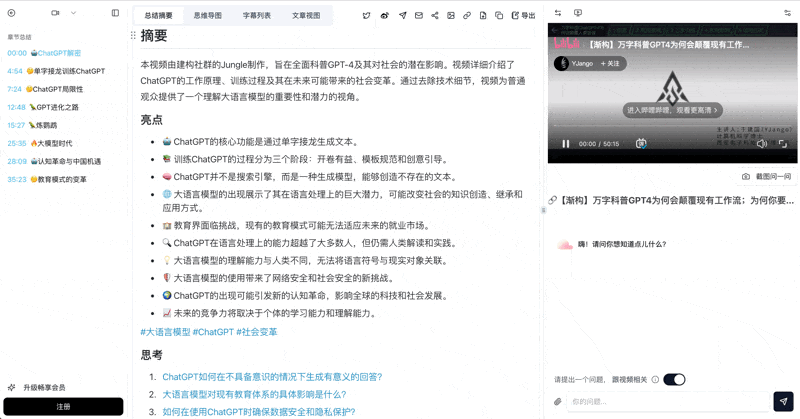
Bilibili: GPT-4 & Workflow Revolution
A deep-dive explainer on how GPT-4 transforms work, covering model internals, training stages, and the societal shift ahead.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeMulti-Engine Transcription Architecture
BibiGPT uses a proprietary multi-engine transcription architecture that automatically selects the optimal transcription engine based on audio characteristics. The addition of OpenAI's Audio Model will further expand engine options — for multi-speaker conversation scenarios, native audio understanding models will significantly outperform traditional ASR.
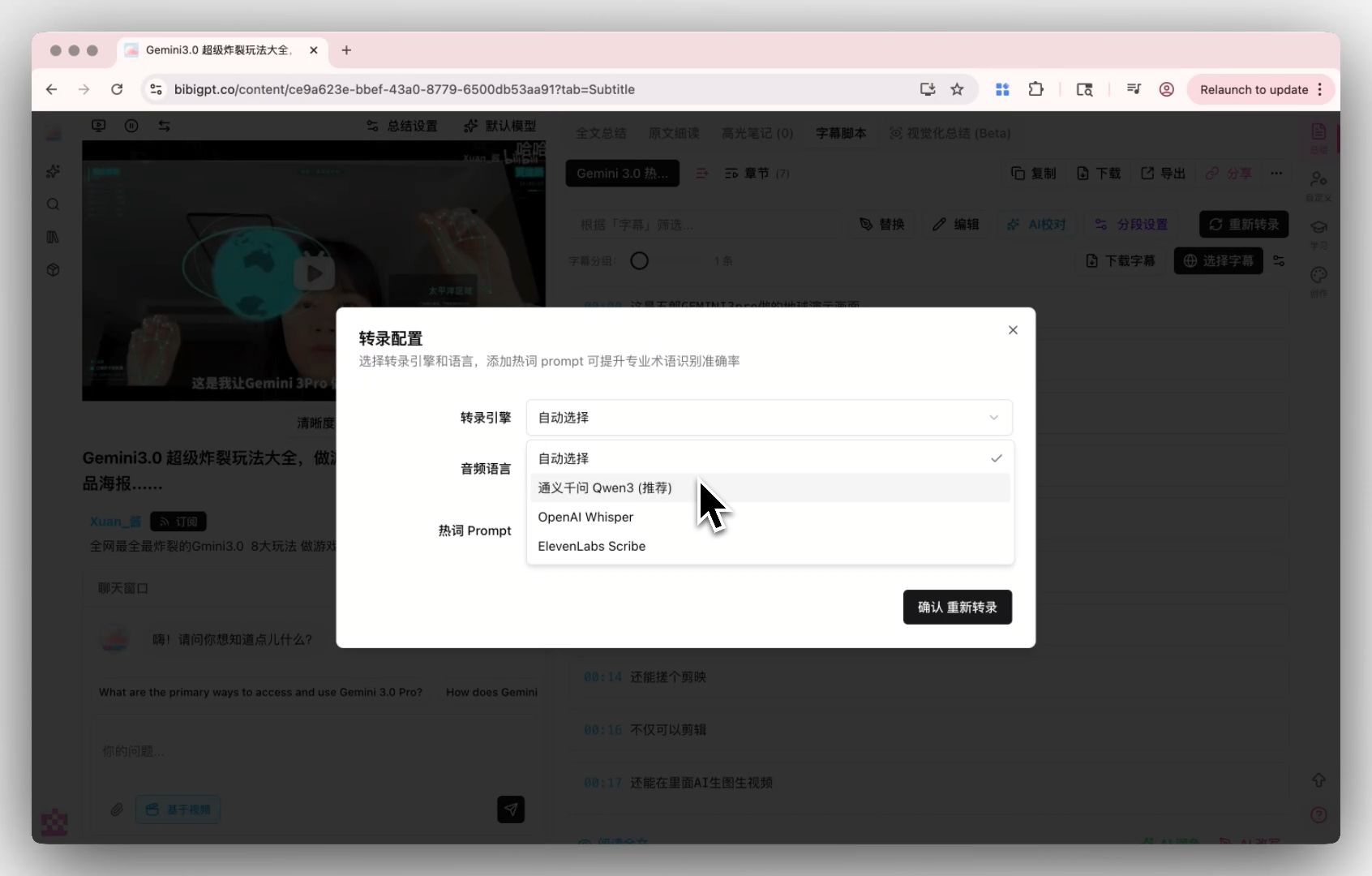 Custom Transcription Engine
Custom Transcription Engine
Podcast-to-Article: From Summaries to Content Creation
Podcast-to-Article is one of BibiGPT's exclusive capabilities. With one click, transform podcast content into well-structured articles ready for publishing on blogs, newsletters, or social media. With audio model upgrades, article accuracy and readability will improve further as the model better grasps speakers' true intentions.
Smart Deep Summary and AI Q&A
BibiGPT's deep summary feature automatically generates core takeaways, highlight extraction, key questions, and terminology glossaries. Combined with the Audio Model's semantic understanding, summaries will more precisely capture a podcast's central arguments rather than stopping at surface-level meaning.
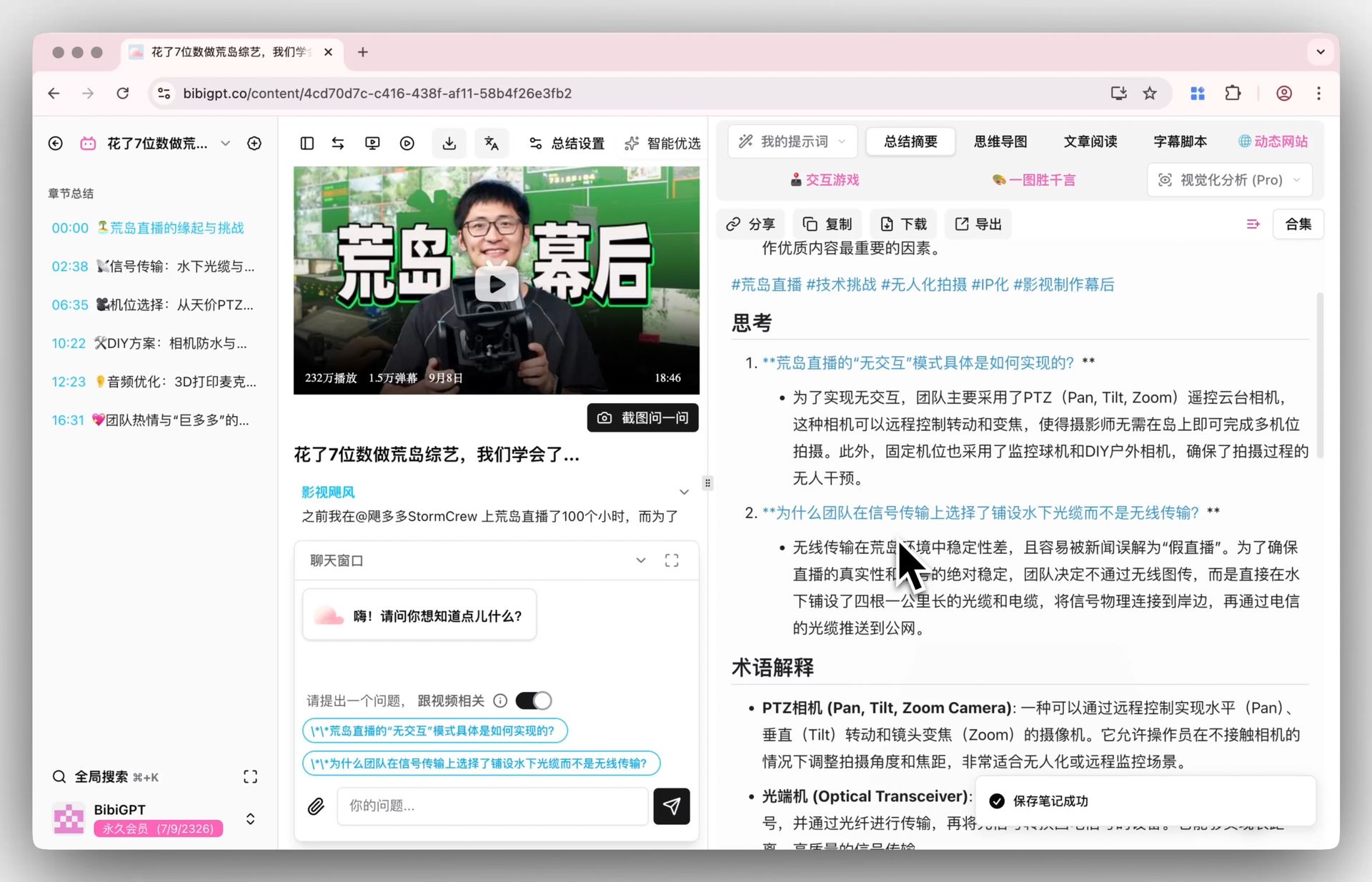 Smart Deep Summary
Smart Deep Summary
Users can also leverage the AI dialogue feature to ask follow-up questions with source tracing, with every answer linked to clickable timestamps for instant navigation to the original audio segment.
Step-by-Step: Summarize Any Podcast in 30 Seconds
Here is the complete workflow for summarizing a podcast with BibiGPT. The entire process takes just 30 seconds:
Step 1: Paste Your Podcast Link
Open aitodo.co and paste any podcast link — Apple Podcasts, Spotify, YouTube, or 30+ other platforms. No plugins or extensions needed.
Step 2: Choose Your Summary Mode
BibiGPT offers multiple output modes: quick summary, deep summary, podcast-to-article, and mind map. Select the one that fits your needs.
Step 3: Get Your Results
Within 30 seconds, you will receive:
- A structured summary with timestamps
- Core arguments and key evidence
- Clickable timestamps linking to specific audio segments
- An AI chat interface for follow-up questions
Step 4: Export and Share
Export your results to Notion, Obsidian, or convert them directly into a published article for your blog or newsletter.
Try BibiGPT podcast summarization now:
- 📎 Paste a podcast link, get a summary in 30 seconds → aitodo.co
- 🎧 Supports Apple Podcasts, Spotify, YouTube, and 30+ more platforms
- 📝 One-click podcast-to-article conversion for instant publishing
What Audio Models Mean for Podcast Creators
OpenAI's Audio Model impacts not just listeners — it carries equally profound implications for podcast creators. Understanding these shifts enables creators to position themselves ahead of the curve, leveraging AI tools to enhance both production efficiency and distribution reach.
Content Repurposing at Scale: With advanced audio understanding, creators can rapidly decompose a single podcast episode into multiple content formats — articles, short video scripts, social media posts, mind maps. BibiGPT's video-to-text converter and podcast-to-article features already help countless creators achieve "record once, distribute everywhere."
Listener Engagement Upgrade: Real-time conversation models signal that podcast consumption will shift from one-way broadcasting to two-way interaction. Listeners will be able to pause and ask AI, "What was the source of that statistic?" — this is exactly what BibiGPT's AI podcast dialogue feature already delivers.
Multilingual Market Expansion: The Audio Model's multilingual capabilities will help podcast content break through language barriers. A single English podcast can rapidly generate summaries in Chinese, Japanese, and Korean, reaching global audiences. BibiGPT already supports multilingual transcription and translation across all major languages.
Podcast AI Tool Selection Guide
With the new wave of tool upgrades driven by audio model advancement, choosing the right podcast AI tool requires evaluating several core dimensions. Needs vary significantly across different use cases, so the key is finding the solution that best fits your specific workflow.
| Dimension | BibiGPT | Traditional Podcast Tools |
|---|---|---|
| Platform Coverage | 30+ audio/video platforms | Usually podcast platforms only |
| Summary Depth | Multi-level (quick/deep/article/mind map) | Single summary |
| AI Chat | Follow-up Q&A + timestamp tracing | Not supported |
| Podcast-to-Article | One-click generation | Not supported |
| Languages | Chinese/English/Japanese/Korean | English primarily |
| Local Files | Upload local audio files | Not supported |
| User Base | 1,000,000+ users | — |
For avid podcast listeners: BibiGPT's deep summary + AI chat combination is the optimal choice, letting you capture podcast insights during fragmented time slots.
For content creators: BibiGPT's podcast-to-article and multi-format export capabilities efficiently transform a single episode into multiple content assets.
For learners: BibiGPT's flashcard generation + Anki export turns podcast knowledge into reviewable memory cards with spaced repetition.
Start your podcast AI journey today:
- 🚀 Try BibiGPT free → aitodo.co
- 🎙️ Supports Apple Podcasts / Spotify / YouTube and 30+ platforms
- ✨ Trusted by 1,000,000+ users with 5,000,000+ AI summaries generated
FAQ
How will OpenAI's Audio Model change podcast AI tools?
The biggest change is the shift from "transcribe first, then understand" to "understand audio directly." This means AI will comprehend podcast content more accurately — detecting tone, emotion, and subtle distinctions in multi-speaker conversations. BibiGPT is actively integrating the latest audio model technology to continuously improve transcription accuracy and summary quality.
What podcast platforms does BibiGPT support?
BibiGPT supports 30+ mainstream audio and video platforms, including Apple Podcasts, Spotify, YouTube, Google Podcasts, and many more. You simply paste a link to get your summary. BibiGPT also supports uploading local audio files for offline recordings, meetings, or lectures.
How long does it take to summarize a podcast with BibiGPT?
Most podcasts are summarized within 30 seconds. For extra-long podcasts (over 2 hours), it may take 1-2 minutes. Results include a structured summary, timestamps, core arguments, and an AI chat interface for follow-up questions.
What is the podcast-to-article feature best used for?
Podcast-to-article is ideal for blog content creation, meeting minutes compilation, study note archiving, and multi-platform content distribution. BibiGPT generates well-structured articles with one click, ready for publishing on any platform.
What does audio model advancement mean for everyday users?
For everyday users, the most tangible change is that AI podcast summaries will be more accurate and insightful. Misunderstandings caused by transcription errors will decrease dramatically, and AI "comprehension" of podcast content will approach human-level understanding. You can experience industry-leading podcast AI capabilities through BibiGPT right now.